


-
Services
Services
Offerings
Learn moreSaaS Development

Web Application Development
Native & Cross-Platform Mobile Apps
Enterprise Software Solutions
API Architecture & Integration
Legacy System Modernization

Time Tracking Web App: Streamlining Productivity with a Custom Enterprise SaaS Solution.
Read case study
Offerings
Learn moreUser Research & Persona Mapping
UX Strategy & Wireframing
UI Design Systems & Libraries
Micro-Interactions & Motion Design
Offerings
Learn moreData Pipeline Design & Development
ETL & Data Warehousing
BI Dashboards & Advanced Reporting
Data Visualization & Analytics
Data Migration & Integration Optimization
Offerings
Learn moreMarketing & Sales Automation
Performance Marketing
Email & WhatsApp Campaigns
SEO & Content Strategy
Analytics & Conversions
CRM Implementation & Integration
Offerings
Learn moreCloud Architecture Design
CI/CD Pipeline Automation
Container Orchestration & Microservices
Cloud Migration & Cost Optimization
AIOps-Powered Intelligence
Cloud Security & Compliance
Share your project details
Share your details with us, and we'll reach out to discuss your needs.
Enquire now
Offerings
Learn moreMachine Learning
Generative AI
Conversational AI & Virtual Agents
Computer Vision Applications
AI-Powered Process Automation
AI Strategy & Consulting
Share your project details
Share your details with us, and we'll reach out to discuss your needs.
Enquire now
- Company



Scope of work
AI-Powered data engineering pipeline
Industry
Insurance / Banking Data Processing
Project timeline
2.5 months
Project goal
99.9%
data consistency
70%
error reduction
Inspired by our work?
Download the full case study.
Table of contents
More from FinTech and Insurance
The Overview
Niva Bupa Health Insurance manages large volumes of insurance data submitted by partner banks and distribution channels. This data is critical for policy issuance, compliance validation, and downstream processing. However, incoming datasets arrive in varied, non-standard formats, creating significant operational complexity.
The engagement focused on building a fully automated, AI-powered data engineering pipeline capable of ingesting raw partner data, intelligently interpreting its structure, and transforming it into a standardized, policy-ready schema, all while maintaining strict data security and regulatory compliance.

The Challenges
Insurance data ingestion at scale introduced several structural and operational challenges.
Key challenges included:
- Inconsistent data formats across partner banks, with varying headers, column orders, and naming conventions.
- Manual processing dependency, where operations teams relied on Excel macros and manual mapping.
- High error rates are caused by header mismatches, missing fields, and formatting inconsistencies.
- Heavy IT involvement is required for onboarding every new partner format or layout change.
- Scalability constraints, as manual workflows could not keep pace with growing data volumes.
- Sensitive data handling requirements demand strict privacy, security, and auditability.
The core issue was not data availability, but the lack of an intelligent, scalable standardization mechanism.
The Objectives
The project was guided by objectives centered on automation, intelligence, and compliance.
The primary objectives were to:
- Build an AI-powered ingestion system that automatically processes raw, unstructured insurance data
- Deploy a self-hosted, open-source LLM to interpret unseen data formats without manual rules
- Enable zero-code data mapping, allowing partners to onboard without IT intervention
- Ensure on-premise AI processing to maintain complete data sovereignty
- Deliver policy-ready, standardized data in near real-time
These objectives ensured operational efficiency without compromising security or compliance.
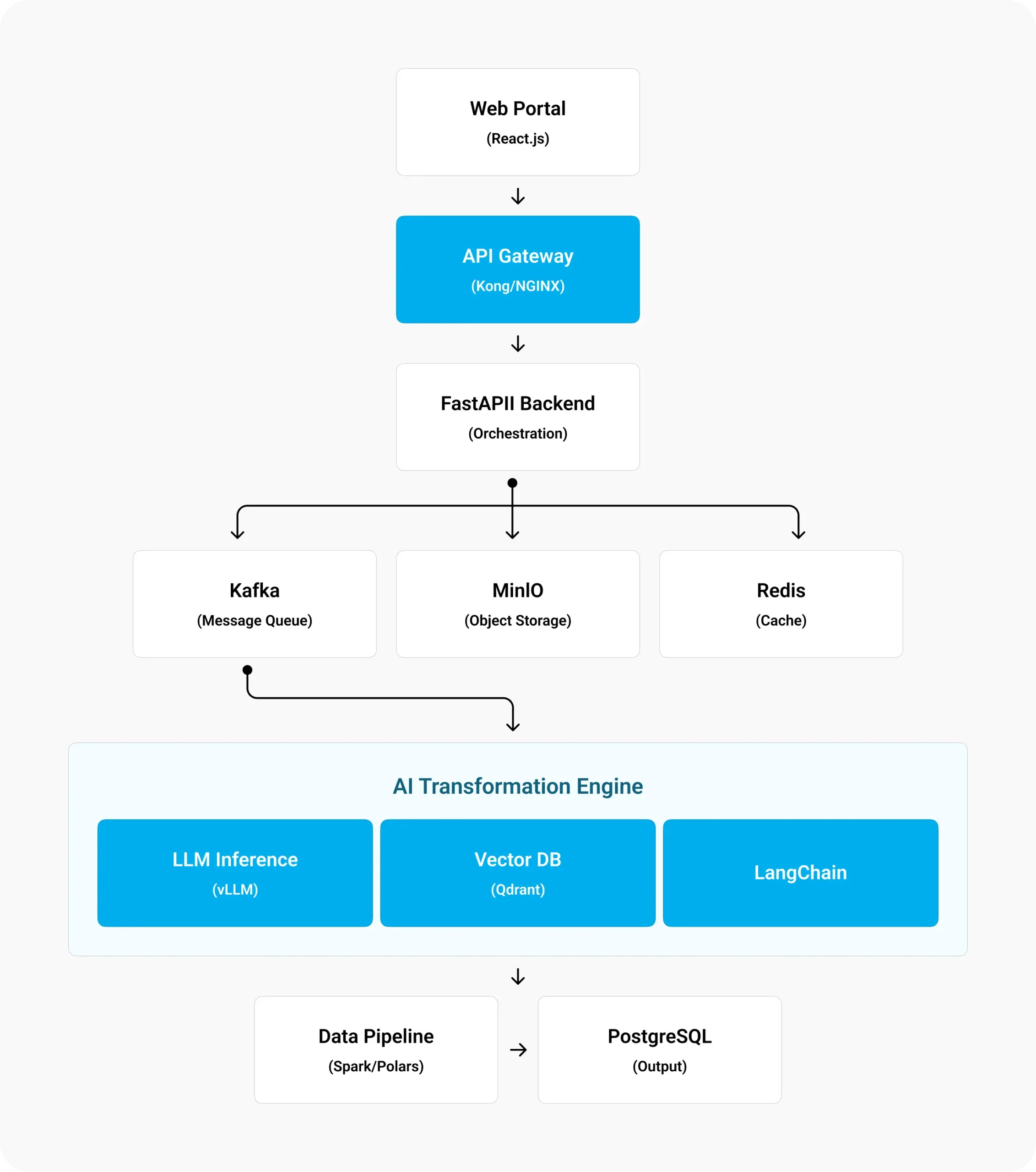
The Solution
The solution was implemented as a multi-layered AI-driven data engineering architecture, combining traditional data pipelines with intelligent language-model reasoning.
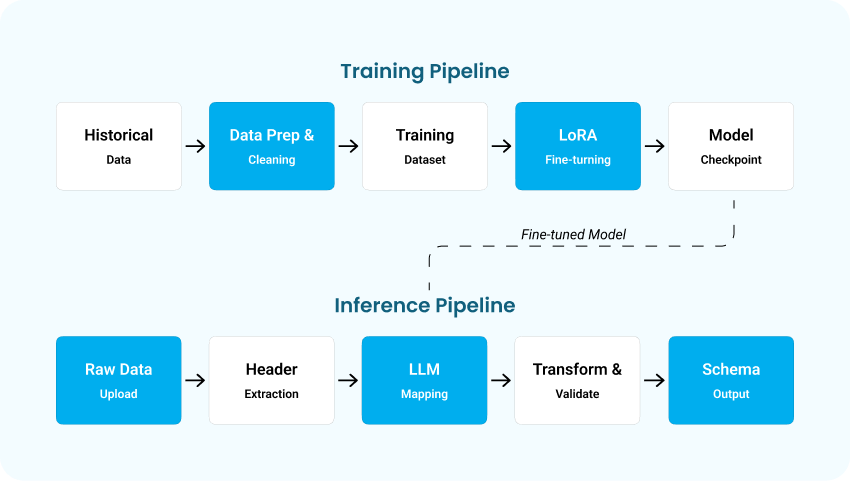
1- AI-Driven Interpretation Layer
At the core of the system is a fine-tuned, open-source LLM deployed on-premises. The model was trained on historical insurance data mappings and enhanced with continuous learning capabilities.
Key capabilities included:
- Intelligent interpretation of column headers and data patterns
- Accurate mapping even for previously unseen partner formats
- Contextual reasoning beyond static rule-based transformations
This eliminated the need for hard-coded mapping logic.
2- End-to-End Data Ingestion Pipeline
Raw datasets uploaded via a secure web portal flow through an automated pipeline that performs:
- Intelligent parsing and structure detection
- Schema transformation and field normalization
- Validation against policy issuance requirements
- Confidence scoring and exception handling
- Loading into a standardized, downstream-ready schema
All processing completes within seconds, dramatically reducing turnaround time.
3- Human-in-the-Loop Quality Control
To balance automation with reliability, a confidence-based review mechanism was implemented.
- High-confidence mappings are auto-approved
- Low-confidence cases are flagged for human review
- Feedback loops continuously improve model accuracy
This ensures quality while minimizing manual effort.
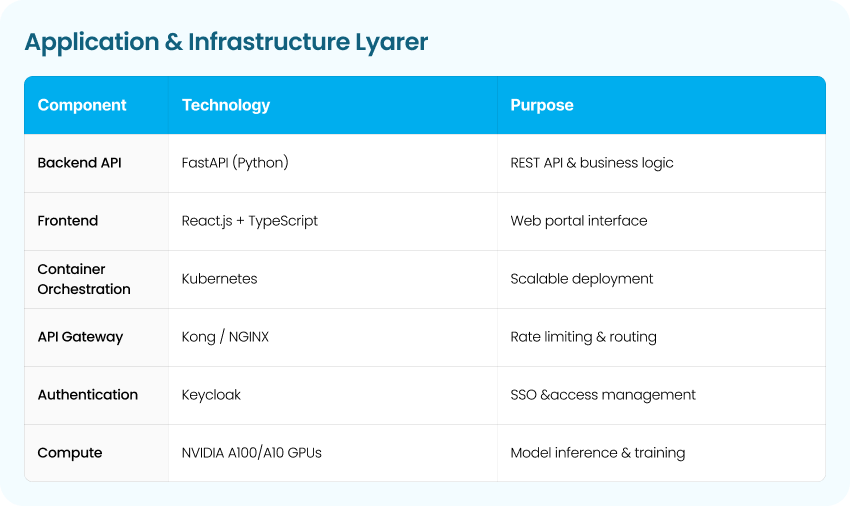
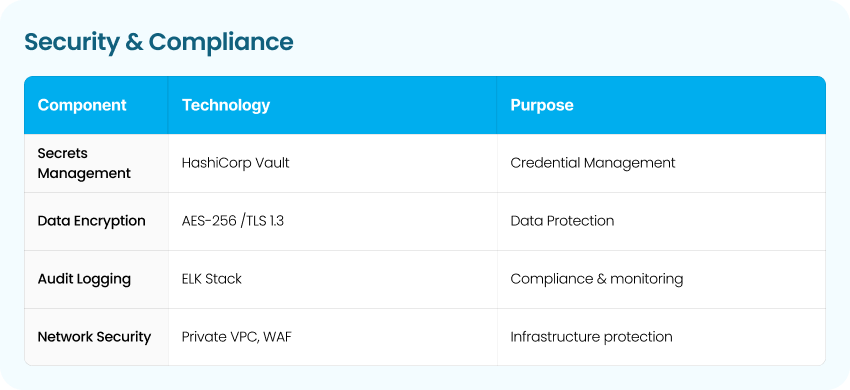
4- Security & Data Sovereignty
Given the sensitivity of insurance and banking data, the entire AI pipeline operates on-premises.
Security measures included:
- Encrypted data at rest and in transit
- No external API calls or third-party AI dependencies
- Full audit trails for every transformation and approval
This architecture ensures regulatory alignment and enterprise-grade security.

The Impact
The AI-powered pipeline delivered measurable operational and strategic gains.
Operational impact included:
- ~90% reduction in manual data processing effort
- Near-instant processing of large insurance datasets
- Elimination of recurring format-related errors
- Zero IT dependency for onboarding new partner formats
Strategic impact included:
- Faster policy issuance cycles
- Improved operational scalability
- Greater resilience to partner-driven format changes
- Long-term cost savings through automation
The system now enables Niva Bupa to confidently scale insurance data intake while maintaining accuracy, speed, and compliance.

Conclusion
This engagement demonstrates how AI-driven data engineering, when combined with on-premises LLM deployment and robust pipeline design, can transform a traditionally manual, error-prone process into a fast, intelligent, and scalable system. By embedding intelligence directly into the ingestion layer, Niva Bupa gained operational efficiency, reduced risk, and future-proofed its insurance data workflows, all while retaining full control over sensitive customer data.
